
enable_raptor.md 4.3KB
sidebar_position: 7
slug: /enable_raptor
Enable RAPTOR
A recursive abstractive method used in long-context knowledge retrieval and summarization, balancing broad semantic understanding with fine details.
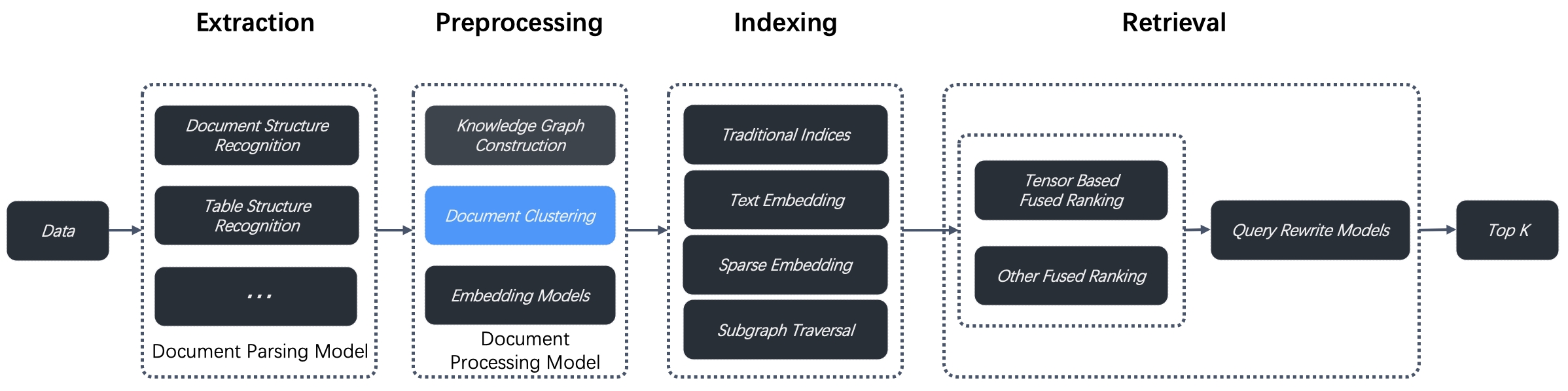
RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) is an enhanced document preprocessing technique introduced in a 2024 paper. Designed to tackle multi-hop question-answering issues, RAPTOR performs recursive clustering and summarization of document chunks to build a hierarchical tree structure. This enables more context-aware retrieval across lengthy documents. RAGFlow v0.6.0 integrates RAPTOR for document clustering as part of its data preprocessing pipeline between data extraction and indexing, as illustrated below.
- Our tests with this new approach demonstrate state-of-the-art (SOTA) results on question-answering tasks requiring complex, multi-step reasoning. By combining RAPTOR retrieval with our built-in chunking methods and/or other retrieval-augmented generation (RAG) approaches, you can further improve your question-answering accuracy.
- :::danger WARNING Enabling RAPTOR requires significant memory, computational resources, and tokens. :::
Basic principles
After the original documents are divided into chunks, the chunks are clustered by semantic similarity rather than by their original order in the text. Clusters are then summarized into higher-level chunks by your system’s default chat model. This process is applied recursively, forming a tree structure with various levels of summarization from the bottom up. As illustrated in the figure below, the initial chunks form the leaf nodes (shown in blue) and are recursively summarized into a root node (shown in orange).
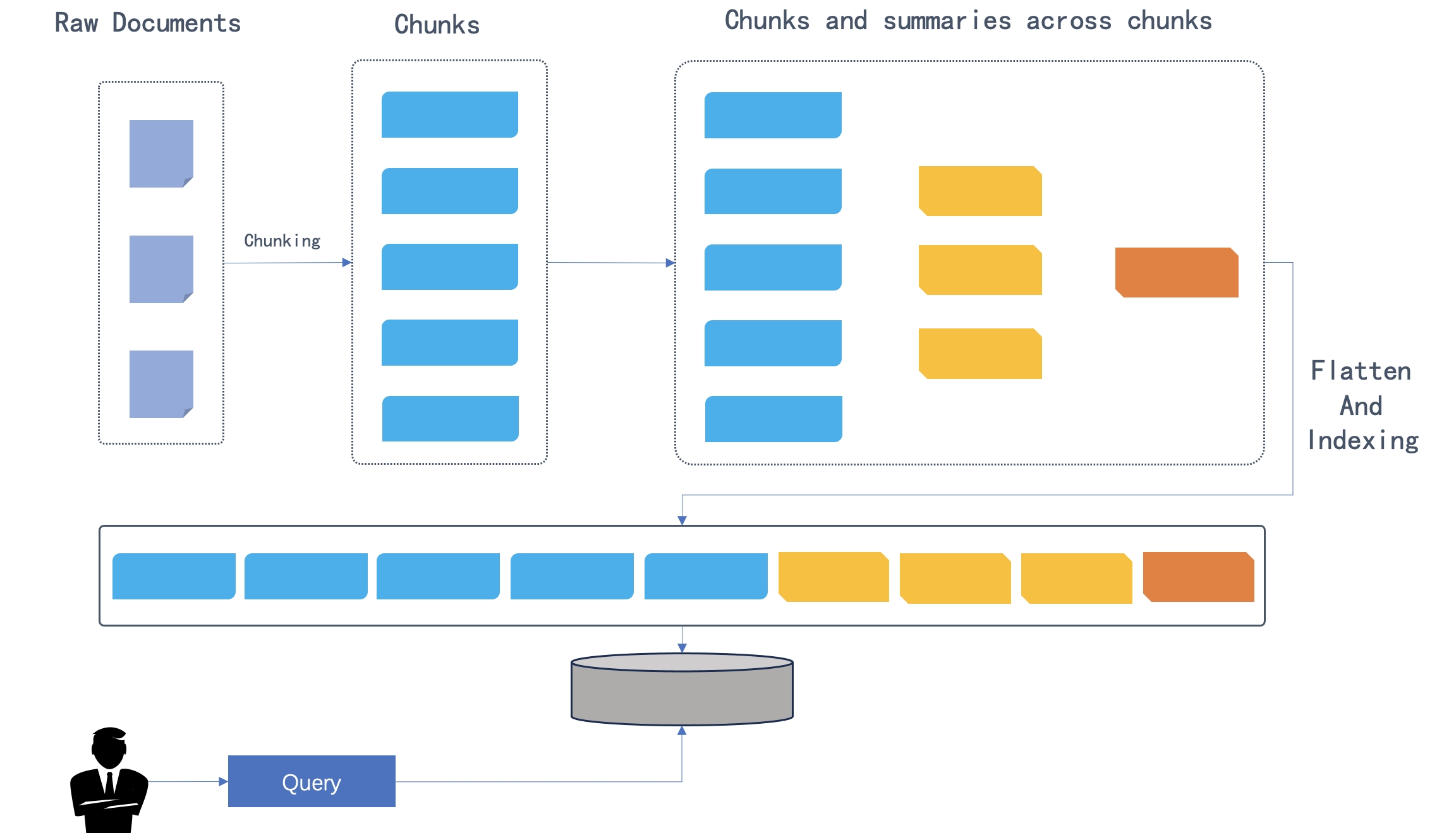
The recursive clustering and summarization capture a broad understanding (by the root node) as well as fine details (by the leaf nodes) necessary for multi-hop question-answering.
Scenarios
- For multi-hop question-answering tasks involving complex, multi-step reasoning, a semantic gap often exists between the question and its answer. As a result, searching with the question often fails to retrieve the relevant chunks that contribute to the correct answer. RAPTOR addresses this challenge by providing the chat model with richer and more context-aware and relevant chunks to summarize, enabling a holistic understanding without losing granular details.
- :::tip NOTE Knowledge graphs can also be used for multi-hop question-answering tasks. See Construct knowledge graph for details. You may use either approach or both, but ensure you understand the memory, computational, and token costs involved. :::
Prerequisites
The system’s default chat model is used to summarize clustered content. Before proceeding, ensure that you have a chat model properly configured:
Configurations
The RAPTOR feature is disabled by default. To enable it, manually switch on the Use RAPTOR to enhance retrieval toggle on your knowledge base’s Configuration page.
Prompt
The following prompt will be applied recursively for cluster summarization, with {cluster_content} serving as an internal parameter. We recommend that you keep it as-is for now. The design will be updated at a later point.
Please summarize the following paragraphs... Paragraphs as following:
{cluster_content}
The above is the content you need to summarize.
Max token
The maximum number of tokens per generated summary chunk. Defaults to 256, with a maximum limit of 2048.
Threshold
In RAPTOR, chunks are clustered by their semantic similarity. The Threshold parameter sets the minimum similarity required for chunks to be grouped together.
It defaults to 0.1, with a maximum limit of 1. A higher Threshold means fewer chunks in each cluster, while a lower one means more.
Max cluster
The maximum number of clusters to create. Defaults to 64, with a maximum limit of 1024.
Random seed
A random seed. Click + to change the seed value.